2026

PnP-CM: Consistency Models as Plug-and-Play Priors for Inverse Problems
Yasar Utku Alcalar*, Merve Gulle*, Junno Yun*, Mehmet Akcakaya (* equal contribution)
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026
We propose PnP-CM, a plug-and-play solver that reinterprets consistency models (CMs) as proximal operators of a learned prior, enabling their seamless integration into plug-and-play (PnP) frameworks. Specifically, PnP-CM is an ADMM-based PnP solver that provides a unified approach to solving a wide range of inverse problems. This is, to the best of our knowledge, the first work to combine consistency models with plug-and-play methods. By incorporating noise perturbations and momentum-based updates, our method is particularly effective in the low-NFE regime. We evaluate PnP-CM on a range of linear and nonlinear inverse problems, including inpainting, super-resolution, Gaussian and nonlinear deblurring, phase retrieval, JPEG restoration, and MRI reconstruction, including the first CM trained on MRI datasets. PnP-CM achieves high-quality reconstructions in as few as 4 NFEs and produces meaningful results in just 2 steps, outperforming existing CM-based solvers.
PnP-CM: Consistency Models as Plug-and-Play Priors for Inverse Problems
Yasar Utku Alcalar*, Merve Gulle*, Junno Yun*, Mehmet Akcakaya (* equal contribution)
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026
We propose PnP-CM, a plug-and-play solver that reinterprets consistency models (CMs) as proximal operators of a learned prior, enabling their seamless integration into plug-and-play (PnP) frameworks. Specifically, PnP-CM is an ADMM-based PnP solver that provides a unified approach to solving a wide range of inverse problems. This is, to the best of our knowledge, the first work to combine consistency models with plug-and-play methods. By incorporating noise perturbations and momentum-based updates, our method is particularly effective in the low-NFE regime. We evaluate PnP-CM on a range of linear and nonlinear inverse problems, including inpainting, super-resolution, Gaussian and nonlinear deblurring, phase retrieval, JPEG restoration, and MRI reconstruction, including the first CM trained on MRI datasets. PnP-CM achieves high-quality reconstructions in as few as 4 NFEs and produces meaningful results in just 2 steps, outperforming existing CM-based solvers.
2025
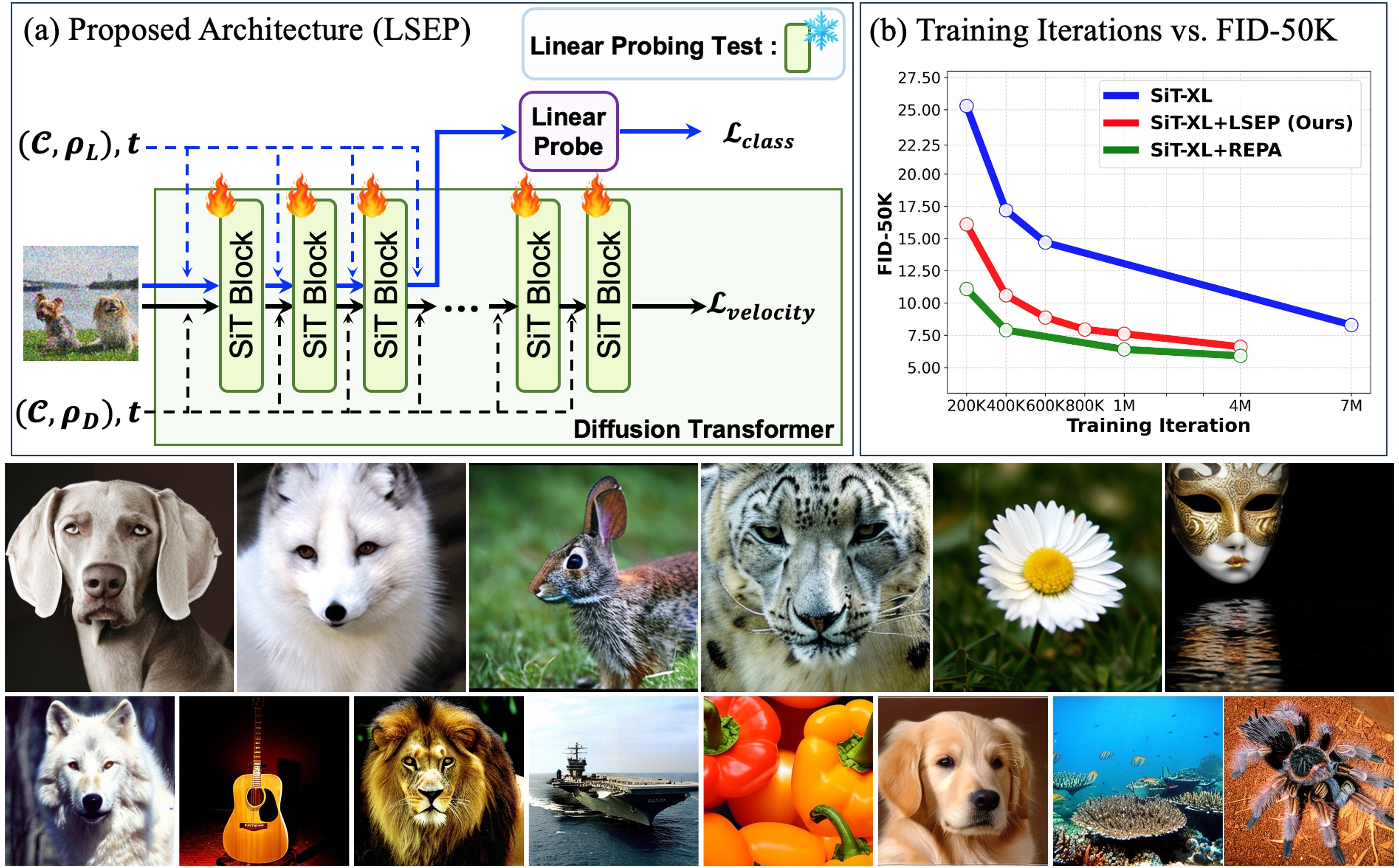
No Alignment Needed for Generation: Learning Linearly Separable Representations in Diffusion Models
Junno Yun, Yasar Utku Alcalar, Mehmet Akcakaya
arXiv preprint 2025
In this work, we present a strategy to improve training efficiency and feature quality in large-scale diffusion models. Our method, LSEP (Linear SEParability), regularizes training by promoting the linear separability of intermediate representations, eliminating the need for external pretrained encoders or alignment-based approaches. By incorporating linear probing directly into the learning process, LSEP enhances both representation quality and generation. Applied to flow-based transformer architectures such as SiTs, LSEP achieves improved efficiency and generation quality, reaching an FID of 1.46 on the 256 × 256 ImageNet dataset.
No Alignment Needed for Generation: Learning Linearly Separable Representations in Diffusion Models
Junno Yun, Yasar Utku Alcalar, Mehmet Akcakaya
arXiv preprint 2025
In this work, we present a strategy to improve training efficiency and feature quality in large-scale diffusion models. Our method, LSEP (Linear SEParability), regularizes training by promoting the linear separability of intermediate representations, eliminating the need for external pretrained encoders or alignment-based approaches. By incorporating linear probing directly into the learning process, LSEP enhances both representation quality and generation. Applied to flow-based transformer architectures such as SiTs, LSEP achieves improved efficiency and generation quality, reaching an FID of 1.46 on the 256 × 256 ImageNet dataset.
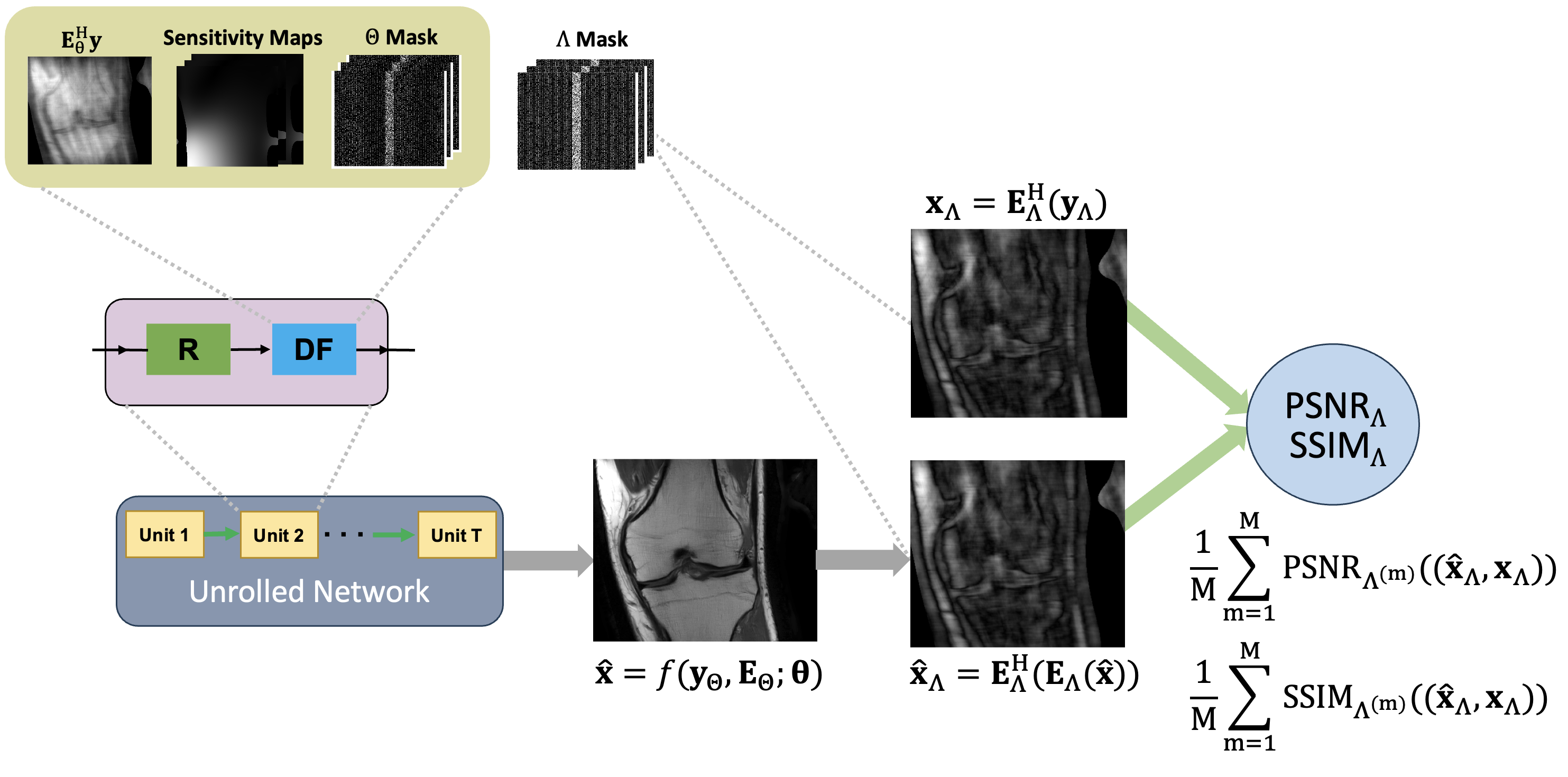
A Self-Validation Metric for Referenceless Image Quality Assessment of Computational Imaging Algorithms
Pranav Salapaka, Yasar Utku Alcalar, Burhaneddin Yaman, Mehmet Akcakaya
59th Asilomar Conference on Signals, Systems, and Computers 2025
Image quality assessment (IQA) is essential for evaluating computational imaging algorithms, but standard metrics like PSNR and SSIM require reference images that are often unavailable in medical imaging. As a result, subjective and time-intensive expert evaluations are commonly used instead. In this work, we propose a referenceless, self-validation metric that masks portions of acquired data and evaluates reconstruction performance on those regions. Experiments in MRI show the metric correlates well with traditional reference-based measures.
A Self-Validation Metric for Referenceless Image Quality Assessment of Computational Imaging Algorithms
Pranav Salapaka, Yasar Utku Alcalar, Burhaneddin Yaman, Mehmet Akcakaya
59th Asilomar Conference on Signals, Systems, and Computers 2025
Image quality assessment (IQA) is essential for evaluating computational imaging algorithms, but standard metrics like PSNR and SSIM require reference images that are often unavailable in medical imaging. As a result, subjective and time-intensive expert evaluations are commonly used instead. In this work, we propose a referenceless, self-validation metric that masks portions of acquired data and evaluates reconstruction performance on those regions. Experiments in MRI show the metric correlates well with traditional reference-based measures.
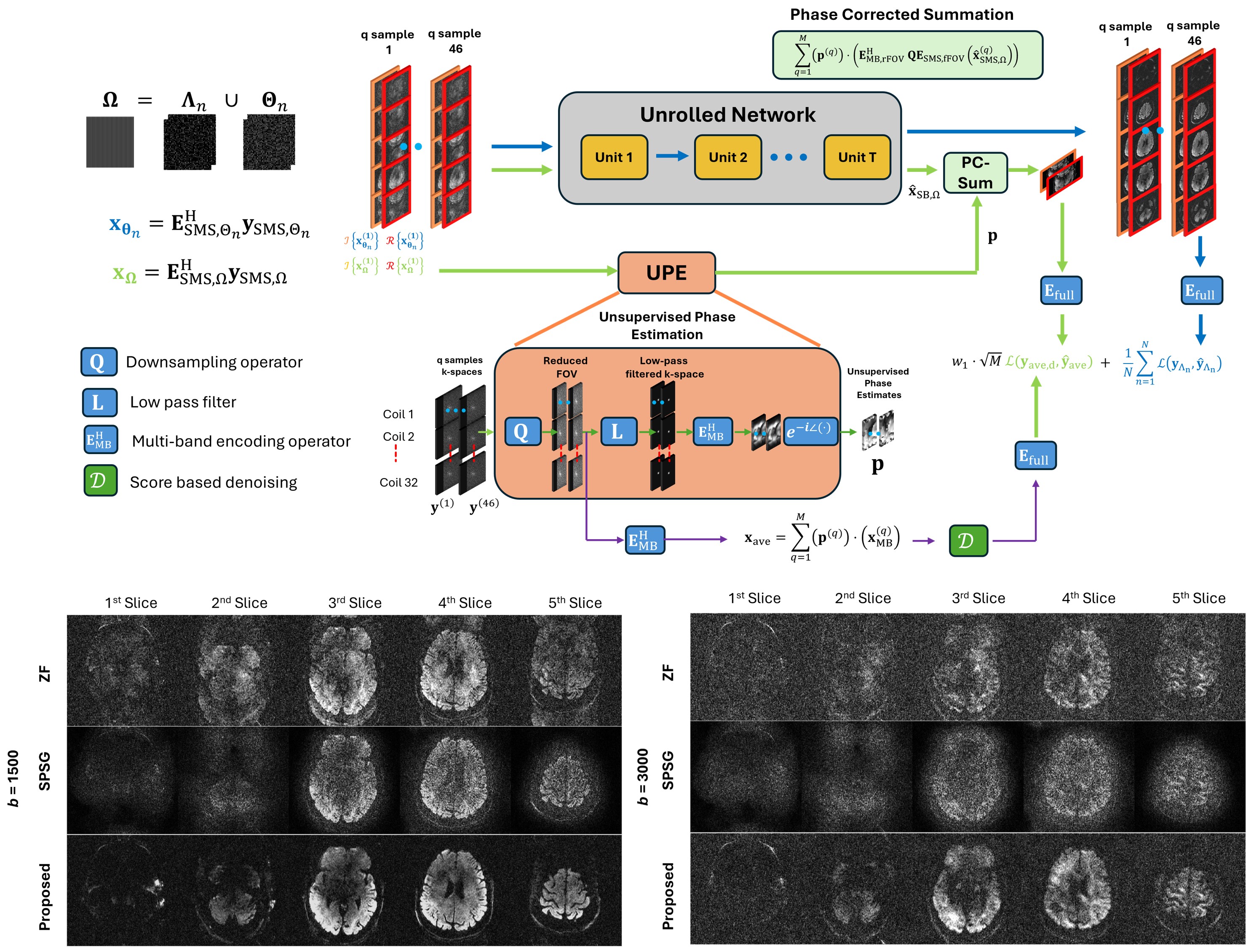
Phase-Adaptive Averaging and Score-Based Denoising for Inverse Problems in Diffusion Imaging
Toygan Kilic, Yasar Utku Alcalar, Steen Moeller, Mehmet Akcakaya
59th Asilomar Conference on Signals, Systems, and Computers 2025
Diffusion magnetic resonance imaging maps brain connectivity but requires many diffusion-weighted images, making high-resolution scans challenging due to low SNR and acceleration limits. Existing AI methods offer limited improvements because of SNR variation across b-values and phase inconsistencies. In this work, we introduced a loss-augmentation strategy that boosts high-b-value SNR using phase-adapted averaging and score-based denoising. Experiments show improved reconstruction quality compared to conventional and standard AI approaches.
Phase-Adaptive Averaging and Score-Based Denoising for Inverse Problems in Diffusion Imaging
Toygan Kilic, Yasar Utku Alcalar, Steen Moeller, Mehmet Akcakaya
59th Asilomar Conference on Signals, Systems, and Computers 2025
Diffusion magnetic resonance imaging maps brain connectivity but requires many diffusion-weighted images, making high-resolution scans challenging due to low SNR and acceleration limits. Existing AI methods offer limited improvements because of SNR variation across b-values and phase inconsistencies. In this work, we introduced a loss-augmentation strategy that boosts high-b-value SNR using phase-adapted averaging and score-based denoising. Experiments show improved reconstruction quality compared to conventional and standard AI approaches.
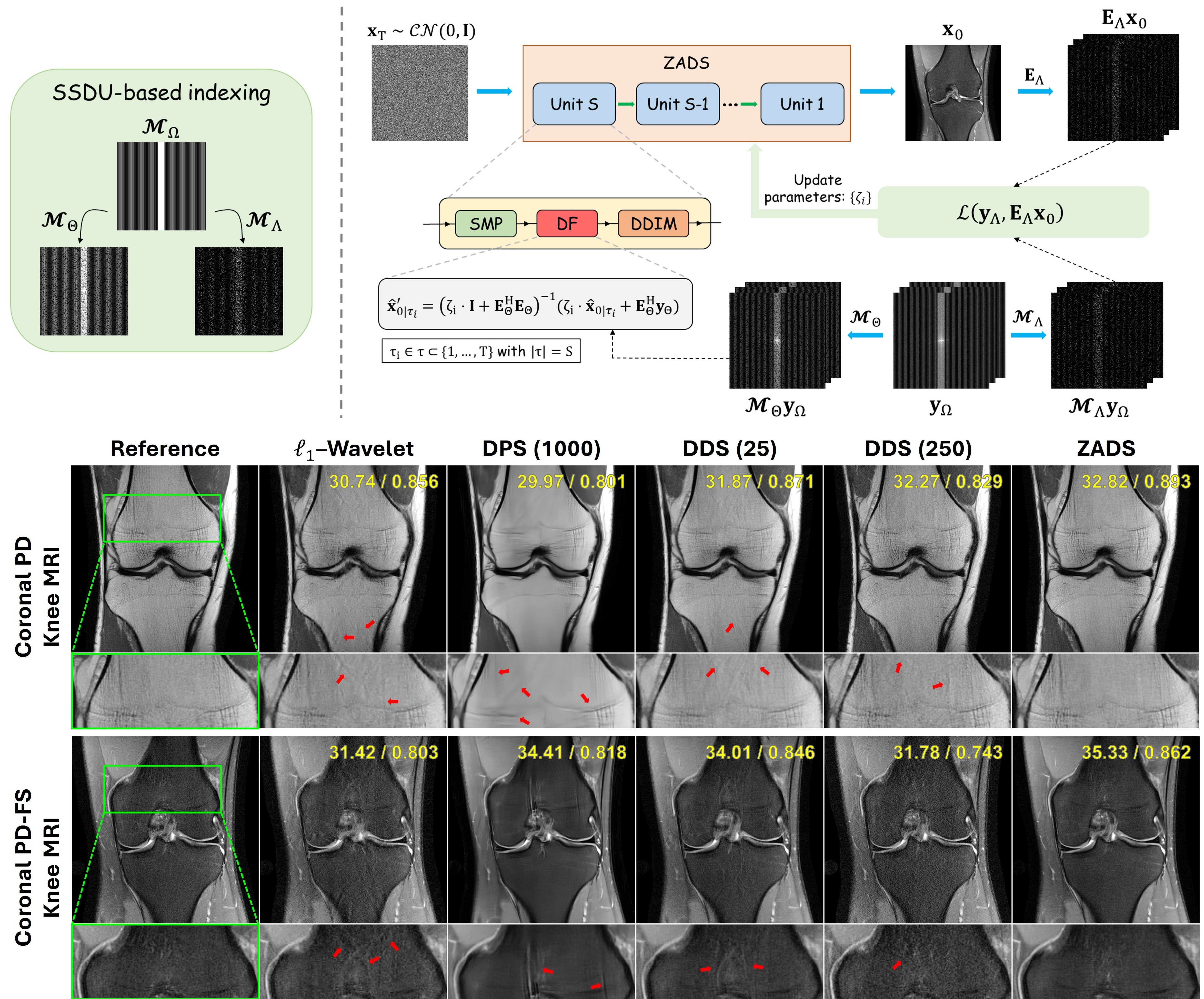
Automated Tuning for Diffusion Inverse Problem Solvers without Generative Prior Retraining
Yasar Utku Alcalar, Junno Yun, Mehmet Akcakaya
IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP) 2025 Best Paper Finalist
We propose Zero-shot Adaptive Diffusion Sampling (ZADS), a self-supervised test-time optimization framework that adaptively tunes data fidelity weights at irregular timesteps without retraining. Unlike our earlier ZAPS method for natural image restoration, which used all acquired measurements, ZADS is tailored for large-scale inverse problems where stronger CG-based updates risk overfitting, motivating hold-out masking. On the fastMRI knee dataset, ZADS achieves state-of-the-art by outperforming recent diffusion-based methods, delivering high-fidelity reconstructions across varying noise schedules and acquisition settings.
Automated Tuning for Diffusion Inverse Problem Solvers without Generative Prior Retraining
Yasar Utku Alcalar, Junno Yun, Mehmet Akcakaya
IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP) 2025 Best Paper Finalist
We propose Zero-shot Adaptive Diffusion Sampling (ZADS), a self-supervised test-time optimization framework that adaptively tunes data fidelity weights at irregular timesteps without retraining. Unlike our earlier ZAPS method for natural image restoration, which used all acquired measurements, ZADS is tailored for large-scale inverse problems where stronger CG-based updates risk overfitting, motivating hold-out masking. On the fastMRI knee dataset, ZADS achieves state-of-the-art by outperforming recent diffusion-based methods, delivering high-fidelity reconstructions across varying noise schedules and acquisition settings.
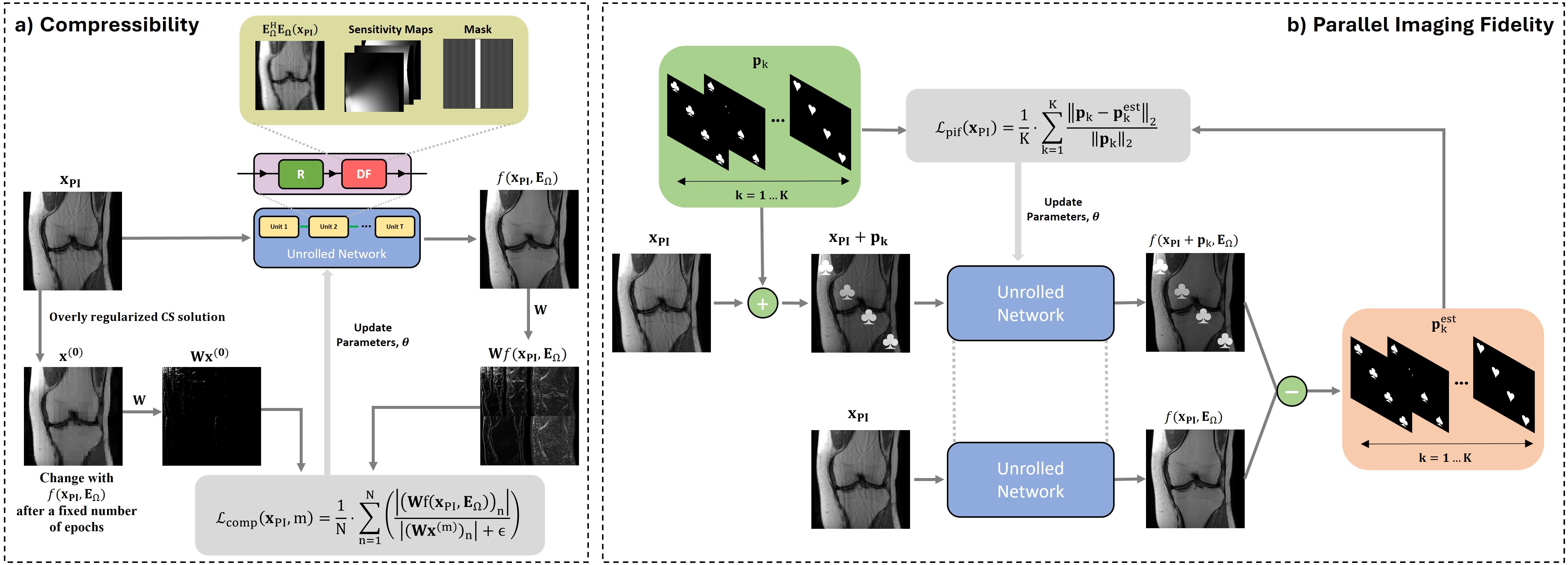
Fast MRI for All: Bridging Access Gaps by Training without Raw Data
Yasar Utku Alcalar, Merve Gulle, Mehmet Akcakaya
Neural Information Processing Systems (NeurIPS) 2025 Spotlight
We propose CUPID, a physics-driven deep learning (PD-DL) method that trains fast MRI reconstruction models using only routine clinical images, without requiring raw k-space data. CUPID leverages compressibility-based quality measures and perturbation-driven consistency with clinical parallel imaging to enable high-quality reconstructions. Experiments show CUPID achieves quality comparable to k-space–based PD-DL methods and surpasses compressed sensing and diffusion approaches, while enabling zero-shot training for retrospective and prospective sub-sampling. By removing the need for raw data, CUPID broadens access to advanced MRI acceleration techniques, particularly for rural and underserved populations.
Fast MRI for All: Bridging Access Gaps by Training without Raw Data
Yasar Utku Alcalar, Merve Gulle, Mehmet Akcakaya
Neural Information Processing Systems (NeurIPS) 2025 Spotlight
We propose CUPID, a physics-driven deep learning (PD-DL) method that trains fast MRI reconstruction models using only routine clinical images, without requiring raw k-space data. CUPID leverages compressibility-based quality measures and perturbation-driven consistency with clinical parallel imaging to enable high-quality reconstructions. Experiments show CUPID achieves quality comparable to k-space–based PD-DL methods and surpasses compressed sensing and diffusion approaches, while enabling zero-shot training for retrospective and prospective sub-sampling. By removing the need for raw data, CUPID broadens access to advanced MRI acceleration techniques, particularly for rural and underserved populations.
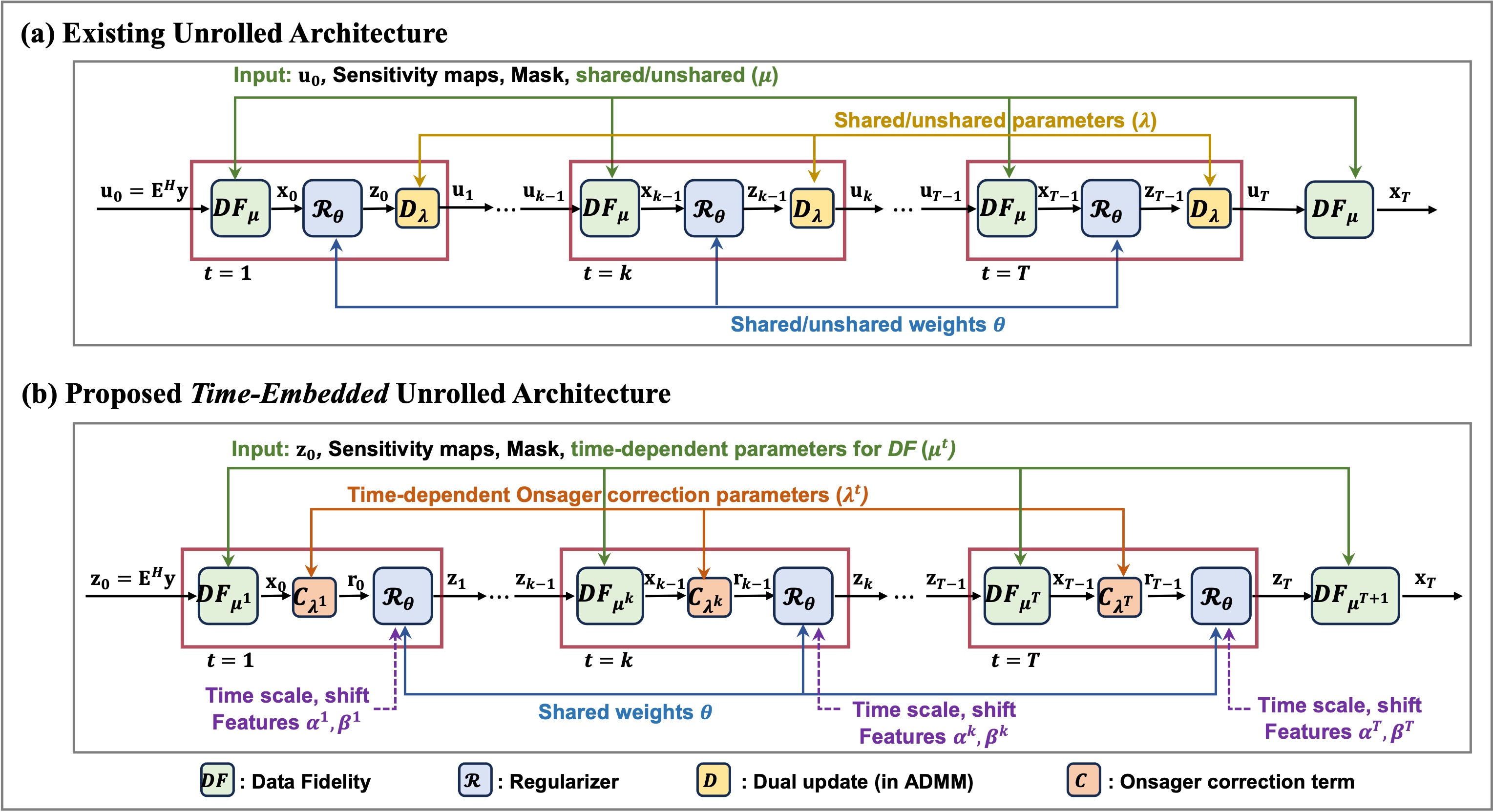
Time-Embedded Algorithm Unrolling for Computational MRI
Junno Yun, Yasar Utku Alcalar, Mehmet Akcakaya
Neural Information Processing Systems (NeurIPS) 2025
We propose a time-embedded algorithm unrolling framework for MRI reconstruction that integrates iteration-dependent proximal operations and data fidelity weights inspired by AMP and diffusion models. By embedding iteration indices into the proximal network and fidelity parameters, our method reduces artifacts and noise while avoiding parameter growth from using distinct networks. Experiments on the fastMRI dataset show state-of-the-art performance across acceleration rates, and the time-embedding strategy further enhances existing unrolling methods without added complexity.
Time-Embedded Algorithm Unrolling for Computational MRI
Junno Yun, Yasar Utku Alcalar, Mehmet Akcakaya
Neural Information Processing Systems (NeurIPS) 2025
We propose a time-embedded algorithm unrolling framework for MRI reconstruction that integrates iteration-dependent proximal operations and data fidelity weights inspired by AMP and diffusion models. By embedding iteration indices into the proximal network and fidelity parameters, our method reduces artifacts and noise while avoiding parameter growth from using distinct networks. Experiments on the fastMRI dataset show state-of-the-art performance across acceleration rates, and the time-embedding strategy further enhances existing unrolling methods without added complexity.
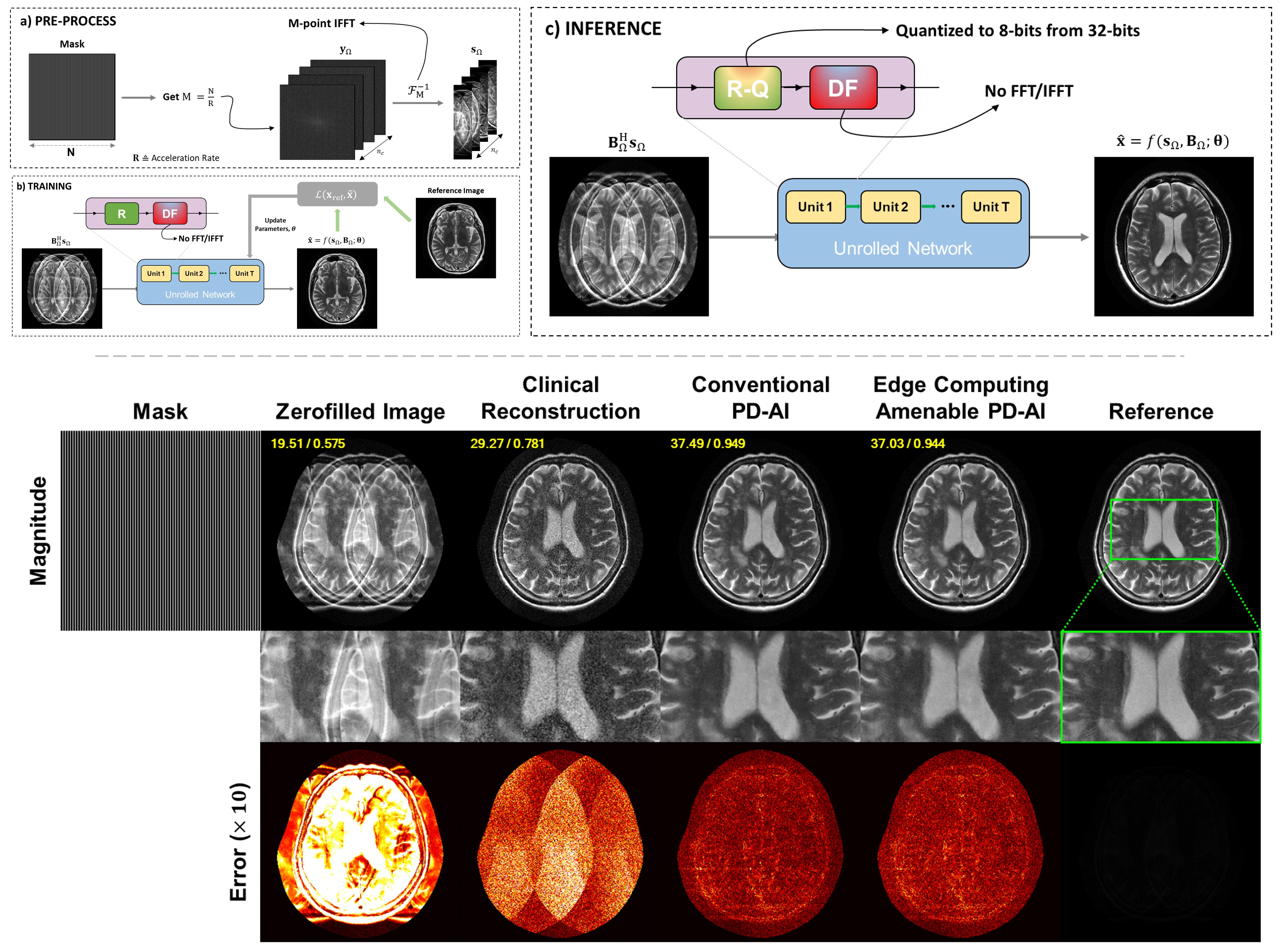
Edge Computing for Physics-Driven AI in Computational MRI: A Feasibility Study
Yasar Utku Alcalar, Yu Cao, Mehmet Akcakaya
IEEE International Conference on Future Internet of Things and Cloud (FiCloud) 2025
We propose a physics-driven AI (PD-AI) reconstruction framework optimized for FPGA-based edge computing to address the massive data demands of high-resolution MRI. Our approach leverages 8-bit complex quantization and eliminates redundant FFT/IFFT operations, improving hardware efficiency without sacrificing reconstruction quality. Results demonstrate performance comparable to conventional PD-AI methods and superior to standard clinical techniques, enabling high-resolution MRI on resource-constrained devices.
Edge Computing for Physics-Driven AI in Computational MRI: A Feasibility Study
Yasar Utku Alcalar, Yu Cao, Mehmet Akcakaya
IEEE International Conference on Future Internet of Things and Cloud (FiCloud) 2025
We propose a physics-driven AI (PD-AI) reconstruction framework optimized for FPGA-based edge computing to address the massive data demands of high-resolution MRI. Our approach leverages 8-bit complex quantization and eliminates redundant FFT/IFFT operations, improving hardware efficiency without sacrificing reconstruction quality. Results demonstrate performance comparable to conventional PD-AI methods and superior to standard clinical techniques, enabling high-resolution MRI on resource-constrained devices.
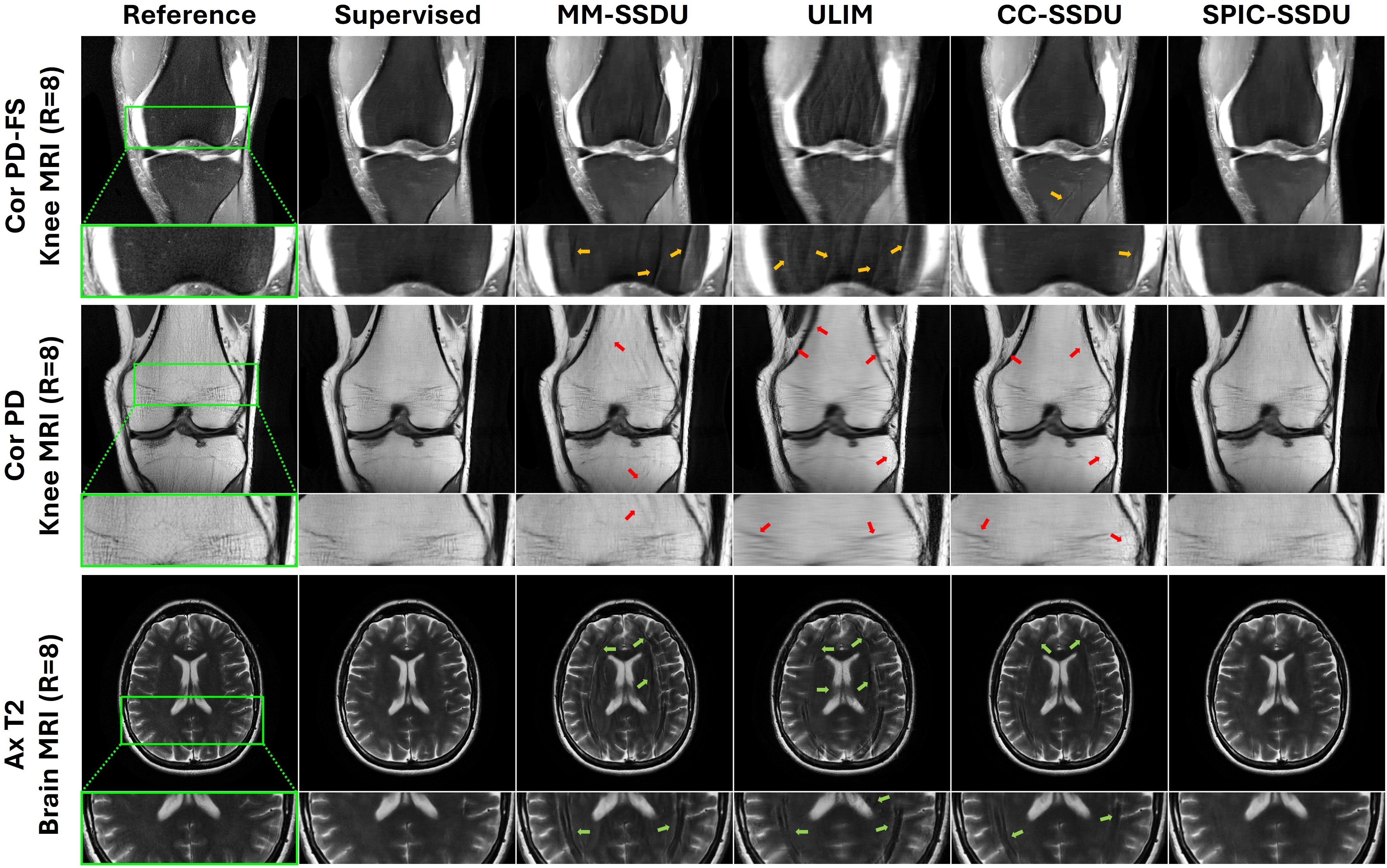
Sparsity-Driven Parallel Imaging Consistency for Improved Self-Supervised MRI Reconstruction
Yasar Utku Alcalar, Mehmet Akcakaya
International Conference on Image Processing (ICIP) 2025 Spotlight Oral
In this work, we introduce a physics-driven deep learning (PD-DL) approach for rapid MRI reconstruction without fully sampled reference data. Our method, SPIC-SSDU, enhances self-supervised training with perturbation-based consistency checks in sparse domains, extending conventional k-space masking with a novel term that evaluates the model’s ability to predict carefully designed additive perturbations. This improves robustness at high acceleration rates, reducing artifacts and noise. Tests on the fastMRI knee and brain datasets show improved image quality over existing self-supervised techniques, achieving performance comparable to supervised learning.
Sparsity-Driven Parallel Imaging Consistency for Improved Self-Supervised MRI Reconstruction
Yasar Utku Alcalar, Mehmet Akcakaya
International Conference on Image Processing (ICIP) 2025 Spotlight Oral
In this work, we introduce a physics-driven deep learning (PD-DL) approach for rapid MRI reconstruction without fully sampled reference data. Our method, SPIC-SSDU, enhances self-supervised training with perturbation-based consistency checks in sparse domains, extending conventional k-space masking with a novel term that evaluates the model’s ability to predict carefully designed additive perturbations. This improves robustness at high acceleration rates, reducing artifacts and noise. Tests on the fastMRI knee and brain datasets show improved image quality over existing self-supervised techniques, achieving performance comparable to supervised learning.
2024

Zero-Shot Adaptation for Approximate Posterior Sampling of Diffusion Models in Inverse Problems
Yasar Utku Alcalar, Mehmet Akcakaya
European Conference on Computer Vision (ECCV) 2024
We introduce ZAPS (Zero-shot Approximate Posterior Sampling), a diffusion-based framework for solving inverse problems with faster inference and improved robustness. Unlike conventional diffusion models that rely on many steps and empirically tuned weights, ZAPS fixes the number of sampling steps and learns log-likelihood weights at each irregular timestep via a physics-guided zero-shot loss. To further reduce computational burden, we approximate the prior Hessian through a learnable diagonalization, enabling efficient training and inference without sacrificing accuracy. Applied to deblurring, inpainting, and super-resolution, ZAPS accelerates inference and improves reconstruction quality over diffusion posterior sampling baselines.
Zero-Shot Adaptation for Approximate Posterior Sampling of Diffusion Models in Inverse Problems
Yasar Utku Alcalar, Mehmet Akcakaya
European Conference on Computer Vision (ECCV) 2024
We introduce ZAPS (Zero-shot Approximate Posterior Sampling), a diffusion-based framework for solving inverse problems with faster inference and improved robustness. Unlike conventional diffusion models that rely on many steps and empirically tuned weights, ZAPS fixes the number of sampling steps and learns log-likelihood weights at each irregular timestep via a physics-guided zero-shot loss. To further reduce computational burden, we approximate the prior Hessian through a learnable diagonalization, enabling efficient training and inference without sacrificing accuracy. Applied to deblurring, inpainting, and super-resolution, ZAPS accelerates inference and improves reconstruction quality over diffusion posterior sampling baselines.
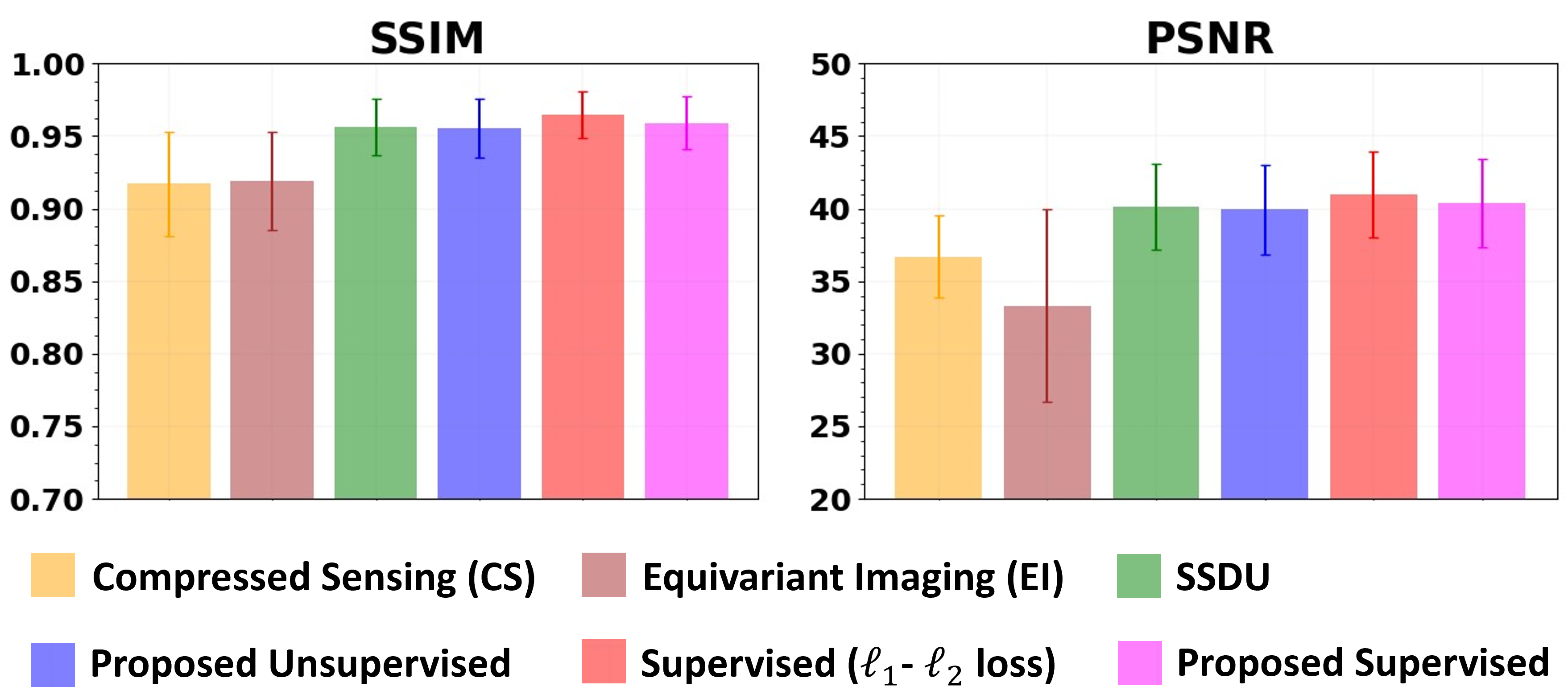
A Convex Compressibility-Inspired Unsupervised Loss Function for Physics-Driven Deep Learning Reconstruction
Yasar Utku Alcalar, Merve Gulle, Mehmet Akcakaya
IEEE International Symposium on Biomedical Imaging (ISBI) 2024
We propose a convex loss function for training physics-driven deep learning (PD-DL) models in fast MRI reconstruction, inspired by statistical image processing and compressed sensing. The loss evaluates image compressibility with a reweighted ℓ1 norm while enforcing data fidelity, enabling supervised, unsupervised, and zero-shot training. PD-DL networks trained with this formulation outperform conventional methods and achieve quality comparable to existing supervised and unsupervised approaches.
A Convex Compressibility-Inspired Unsupervised Loss Function for Physics-Driven Deep Learning Reconstruction
Yasar Utku Alcalar, Merve Gulle, Mehmet Akcakaya
IEEE International Symposium on Biomedical Imaging (ISBI) 2024
We propose a convex loss function for training physics-driven deep learning (PD-DL) models in fast MRI reconstruction, inspired by statistical image processing and compressed sensing. The loss evaluates image compressibility with a reweighted ℓ1 norm while enforcing data fidelity, enabling supervised, unsupervised, and zero-shot training. PD-DL networks trained with this formulation outperform conventional methods and achieve quality comparable to existing supervised and unsupervised approaches.